
Validität und Konfidenzintervalle
Auf dem Korridor stoßen wir auf eine Tür mit der Aufschrift „Externe und interne Validität“. Neben Erklärungen und einigen Graphiken finden wir das Modell eines Bauernhofes mit Traktoren und vielen kleinen lustigen Figuren, was uns so sehr aufmuntert, dass wir mit Begeisterung die Ausführungen lesen.
Was verstehen wir unter Validität? Validität heißt in unserem Zusammenhang so viel wie Richtigkeit bzw. Gültigkeit. In der Regel wird „valide“ als Adjektiv verwendet. Eine valide Messung ist eine richtige bzw. gültige Messung, bei der tatsächlich dasjenige gemessen wurde, was beabsichtigt war. Ein valider Test bestimmt dasjenige, wozu er vorgesehen ist. Ein valides Argument ist ein gültiges Argument, weil es zutrifft. Eine valide Schlussfolgerung ist eine gültige Folgerung aus den bekannten Fakten.
Gute Daten sollten insgesamt drei Gütekriterien erfüllen: sie sollten objektiv, verlässlich und valide sein. Objektive Daten zeichnen sich dadurch aus, dass sie durch eine Messung erhoben werden, die nicht direkt vom Beobachter beeinflusst wird. Die subjektive Komponente tritt hier in den Hintergrund. Die Daten hängen also nicht primär von der zu untersuchenden Person ab. Wenn wir keine Objektivität unterstellen können, sondern Subjektivität vermuten, dann sind die Daten immer nur relativ zum Untersucher gültig und schlecht übertragbar. Von verlässlichen oder reproduzierbaren Daten über einen Gegenstand sprechen wir dann, wenn wir bei wiederholten Messungen dieselben Ergebnisse erhalten. Die Verlässlichkeit oder Reliabilität ist die Voraussetzung dafür, dass wir Studien wiederholen können und dabei dieselben Daten erheben. Von validen Daten sprechen wir, wenn wir glauben, dass wir tatsächlich dasjenige gemessen haben, was wir beabsichtigt haben. Da wir keine der Gütekriterien als gegeben annehmen dürfen, sollten wir immer überprüfen, ob sie tatsächlich vorliegen.
Daten können valide sein oder nicht, und sie können verlässlich sein oder nicht. Die vier möglichen Kombinationen der Eigenschaften „valide“ und „verlässlich“ sind in der Abbildung 13-1 in Form von Zielscheiben zusammengefasst. Hier wird ein Schießwettbewerb simuliert, um die Bedeutung der Validität und Reliabilität zu erläutern.

Abb. 13-1 Valide und verlässliche Schüsse auf eine Zielscheibe
Wenn wir mit dem Gewehr immer das anvisierte Ziel verlässlich treffen, dann werden die Einschüsse in der Nähe des Ziels liegen, nämlich in der Mitte der Zielscheibe (A). Sollte die Waffe stark streuen und somit weniger verlässlich sein, dann werden sich die Einschüsse weiter weg um die Mitte der Zielscheibe gruppieren (B). Wenn die Waffe dagegen nicht „valide“ ist und einen krummen Lauf aufweist, dann schießen wir immer neben das Ziel. Ist die Waffe dabei sehr verlässlich, dann treffen wir immer genau daneben (C). Sollte die Waffe auch noch stark streuen, dann könnten wir zufällig auch das Ziel treffen (D). Es ist keine Frage, dass wir eine Waffe bevorzugen, die nicht streut und keinen krummen Lauf hat. Und genauso verhält es sich auch mit erhobenen Daten. Wir suchen valide und verlässliche Daten, wobei sowohl die Validität als auch die Reliabilität von den Messverfahren abhängen, die wir verwenden.
Wenn wir zum Beispiel den Hämoglobingehalt des Blutes messen, dann verlassen wir uns auf die ausgereiften Techniken der Labormedizin und erwarten immer ein valides und verlässliches Ergebnis. Wenn wir dagegen wechselnde Befindlichkeiten oder die Lebensqualität der Patienten in verschiedenen Lebenssituationen erfassen wollen, dann können wir nicht einen beliebigen Score auswählen oder uns einen plausiblen Fragenkatalog ausdenken, um valide Daten zu erhalten. Wir sollten uns nicht darauf verlassen, dass solche ad-hoc Scores valide Ergebnisse generieren. Wir sollten eher auf ein bereits validiertes Testverfahren zurückgreifen, das in aufwendigen Versuchen daraufhin überprüft wurde, dass es tatsächlich dasjenige misst, für das es vorgesehen ist.
13.1 Interne Validität
Was meinen wir mit „interner Validität unserer Folgerungen“ und wovon hängt sie ab? Was drücken wir aus, wenn wir die interne Validität bestätigen? Dieser Begriff lässt sich gut erklären, wenn wir uns noch einmal an unsere Situation erinnern. Wir haben eine konkrete Frage über eine Gesamtpopulation. Wir wollen zum Beispiel für diese Patientengruppe wissen, ob ein bestimmtes Medikament oder Operationsverfahren besser wirkt als ein anderes. Da wir nicht alle Patienten in die Studie aufnehmen können, ziehen wir eine repräsentative Stichprobe. Dann beginnen wir mit der Studie, generieren valide Daten und ziehen Schlussfolgerungen. Wenn diese korrekt sind, dann sprechen wir von der internen Validität der Schlussfolgerungen. Diese interne Validität bezieht sich somit immer nur auf die Schlussfolgerungen, die wir aus den Daten der Studienteilnehmer gezogen haben. Die interne Validität gründet sich auf die interne Qualität der Studie. Sie bleibt letztlich auf die Studienpopulation beschränkt.
Wie gelangen wir zu einer hohen internen Validität? In erster Linie durch hochwertige Studien. Wenn wir zum Beispiel überprüfen wollen, ob die Entstehung von Krebs auf Umwelteinflüsse, bestimmte Toxine oder Strahlungen zurückgeführt werden können, dann sollte sichergestellt sein, dass nicht andere, alternative, unberücksichtigte Faktoren die Krebsentstehung beeinflussen. Valide Folgerungen können wir nur ziehen, wenn uns keine methodischen Fehler in der Studie unterlaufen sind und wir alle bekannten Einflussgrößen berücksichtigt haben. Alle Störgrößen sollten ausgeschaltet worden sein, soweit es irgend möglich ist, und die verglichenen Gruppen sollten in den wesentlichen Merkmalen homogen verteilt werden, was uns am besten durch eine geeignete Randomisierung gelingt.
Wenn wir eine Studie sorgfältig planen, dann versuchen wir sicher zu stellen, dass durch geeignete Messverfahren valide und verlässliche Daten erhoben werden können. Was natürlich nicht ausschließt, dass bei Unregelmäßigkeiten in der Durchführung der Studie auch nicht-valide Daten entstehen können. Deshalb sollten wir die einzelnen Studien kritisch daraufhin durchsehen, ob Unregelmäßigkeiten aufgetreten sein können. Nur von einer qualitativ hochwertigen Studie können wir erwarten, dass sie verlässliche und valide Daten generiert. Die Ergebnisse einer schlampig durchgeführten Studie sollten grundsätzlich nicht verwendet werden, weil sie massiven Störeinflüssen ausgesetzt sein könnten, so dass wir die Daten nicht sinnvoll interpretieren können. Gravierende Irrtümer und missverständliche Schlussfolgerungen werden nicht selten durch solche Studien verursacht.
Es gibt immer die Möglichkeit, dass Studienergebnisse unbewusst und unbeabsichtigt beeinflusst wurden. Es ist eine Frage der optimalen Versuchsplanung und des professionellen Studiendesigns, solche Situationen zu vermeiden und die interne Validität sicherzustellen. Es soll hier noch einmal betont werden, dass eine Studie wertlos ist, wenn die Daten und daraus folgenden Argumente nicht valide sind.
13.2 Externe Validität
Wir interessieren uns aber nicht nur für die Ergebnisse der Studienteilnehmer. Wir haben die Studie auch durchgeführt, um Schlussfolgerungen auf alle Patienten bzw. die Grundgesamtheit zu ziehen, die ähnliche Erkrankungen aufweisen, wie die Patienten, die in der Studie eingeschlossen wurden. Und wir wollten in der Studie feststellen, welche Therapie zur Behandlung besser geeignet ist. Aufgrund dieses neuen Wissens würden wir dann Patienten behandeln, die nicht in die Studie aufgenommen wurden. Wir schließen mithin von den Daten der Studie auf die gesamte Population. Wir übertragen unsere internen Schlussfolgerungen auf alle Erkrankten. Vorher sollten wir aber überprüfen, ob dieser externe Schluss auch gültig bzw. valide ist. Wir sollten die externe Validität der Folgerungen überprüfen. Unter externer Validität verstehen wir die Allgemeingültigkeit der internen Folgerungen. Externe Validität können wir mit Verallgemeinerungsfähigkeit übersetzen. Eine hohe externe Validität einer Studie bedeutet, dass wir die Ergebnisse einer Studie auf die Grundgesamtheit übertragen können und dass sie diesbezüglich sehr gut verallgemeinerungsfähig sind.

Selbst wenn die interne Validität eindeutig gesichert ist, dann muss das nicht auch zwangsläufig für die externe Validität gelten. Auf den ersten Blick scheint die externe Validität immer gesichert, denn wenn wir eine repräsentative Stichprobe von der Grundgesamtheit gezogen haben, dann dürften mit der externen Validität keine Probleme auftreten. Das mag verwundern, ist aber leicht zu erklären, wenn wir den Blick in die richtige Richtung lenken. Bei der internen Validität ging es uns um eine perfekte Studie. Wir wollten wissen, ob bestimmte Faktoren ein definiertes Ergebnis beeinflussen. Wir haben deshalb ein homogenes Patientengut ausgewählt, um genau diese Frage zu beantworten. Dadurch haben wir bewusst ein spezielles Patientengut ausgewählt, dass in dieser Konstellation im klinischen Alltag wahrscheinlich weniger häufig auftritt.
Wir müssen beachten, dass die interne und externe Validität zwei Konkurrenten sind. Wenn wir eine sehr gute hochkontrollierte Studie bei einem ausgewählten Patientengut vornehmen, dann können wir mit ziemlich hoher Sicherheit feststellen, ob eine bestimmte Therapie besser ist als eine andere. Je „künstlicher“ die Studienbedingungen sind, umso mehr Faktoren können wir kontrollieren und umso weniger Störgrößen treten auf. Störgrößen sind äußerst unerwünscht, weil wir am Ende nicht wissen, ob Unterschiede aufgrund der Störgrößen aufgetreten sind oder weil ein Verfahren besser ist.
Jetzt sollten wir einen Blick auf das Kleingedruckte der externen Validität werfen. Streng genommen ist die Übertragbarkeit der Ergebnisse immer nur auf dasselbe Krankengut gestattet, wobei im klinischen Alltag sehr häufig dagegen verstoßen wird. In den meisten Studien werden sehr viele Patienten ausgeschlossen und hochwertige Studien zeichnen sich zum Teil durch eine extreme Selektion aus. Die Patienten, die in Studien aufgenommen werden, werden deshalb so genau ausgewählt, weil komplexe Komorbiditäten gemieden werden sollen, die das Ergebnis unkontrolliert beeinflussen können. Aber genau das sind die Kranken, die wir überall antreffen. Die nicht-selektierten Patienten sind sehr viel häufiger als die Patienten, die in Studien eingeschlossen wurden. Achten Sie zukünftig einmal auf das Zahlenverhältnis zwischen den potentiellen Studienteilnehmer und den tatsächlichen Teilnehmern. Das Verhältnis schwankt von 1:3 bis 1:20. Wie sollen wir Ergebnisse interpretieren, wenn nur jeder zwanzigste geeignete Patient in eine Studie aufgenommen wurde. In späteren Abschnitten werden wir noch darauf eingehen.
Die Pharma- und Industrievertreter kümmern sich wenig um die externe Validität und versuchen mit geeigneten Marketingstrategien, die positiven Ergebnisse ihrer Studien und mit ihrer hohen internen Validität unter die Menschen zu bringen. Sonderdrucke im Hochglanzdruck werden auf Kongressen oder persönlichen Besuchen stoßweise angeboten. Aber nur deshalb, weil die Vertreter wissen, dass die Studien doch nicht gelesen oder nicht hinreichend verstanden werden – was uns jetzt nicht mehr geschehen sollte.
Wie wichtig das Verständnis der externen Validität ist, wollen wir an einer kleinen Geschichte aus der Landwirtschaft verdeutlichen: Es war einmal ein junger dynamischer und erfolgreicher Landwirt im thüringischen Umland mit einer großen Ackerfläche, die schon seit Generationen von seiner Familie bewirtschaftet wurde. Wegen einer Investition zog er seinen promovierten Schwager zu Rate, der als Pharmakologe in einem Labor forscht. Der Landwirt besaß einen „alternden“ Traktor und ein veraltetes Pflugsystem, mit dem bereits sein Vater das Land bestellt hatte. Aufgrund seiner guten ökonomischen Lage dachte der Landwirt über den Kauf eines neuen Traktors nach, denn er befürchtete baldige teure Reparaturen des alten. Außerdem protzte sein Nachbar bereits mit einem neuen, größeren Traktor. Nachdem er seine Kauflust signalisiert hatte, besuchte ihn ein eloquenter Verkaufsberater mit Hochglanzbroschüren und empfahl einen Hochleistungstraktor mit einem neuartigen Pflugsystem, der die Arbeitszeit um 25 Prozent verkürzen und die Ernte um 15 Prozent erhöhen soll. Nach dem Gespräch fragt er den Schwager, ob man den Ausführungen des Fachverkäufers vertrauen und den neuen Traktor kaufen sollte. Natürlich äußerte der Schwager seine Skepsis und riet ihm, sich darüber zu informieren, woher man denn so genau wüsste, dass sich die Arbeitszeit verringert und die Ernte erhöht. Vielleicht wäre auch eine Probestellung für ein Jahr möglich, um die Funktionalität vor Ort eingehend zu prüfen.
Vier Monate später besuchte der Landwirt seinen Schwager und teilte ihm erfreut mit, dass er seinem Rat gefolgt sei. Er hatte sich zwei wissenschaftliche (randomisierte) Studien vorlegen lassen, die eindeutig belegten, dass die genannten Effekte (Arbeitsverkürzung und Erntesteigerung) sicher eintreten werden. Überzeugt durch die Studien hatte er sich den neuen Traktor angeschafft. Ein Jahr später trafen sich beide auf einer Familienfeier wieder. Auf die Frage des Schwagers nach dem neuen Traktor druckste der Landwirt etwas herum. Seine Begeisterung schien einer gewissen Ernüchterung gewichen zu sein, denn der neue, größere und schwerere Traktor erwies sich nur in 30 Prozent seiner Ackerflächen als sehr gut nutzbar. Da seine Bebauungsflächen im hügeligen Gelände liegen und der Boden zum Teil sehr versteint ist, kann er den neuen Traktor hier nur mühsam einsetzen. In einigen Bereichen musste er bereits den alten Traktor „revitalisieren“, damit er das Feld überhaupt bearbeiten konnte. Aber für das nächste Jahr versprach sich der Landwirt eine deutliche Verbesserung, denn er führte die Schwierigkeiten auf die mangelnde Erfahrung mit dem neuen Traktor zurück. Daraufhin bat ihn der Schwager, bei seinem nächsten Besuch die überzeugenden Studien mitzubringen.
Ein weiteres Jahr später war der Landwirt richtig frustriert, weil der Traktor letztlich nur bei 30 Prozent sehr gut und bei weiteren 20 Prozent mäßig gut einsetzbar war. Für die restlichen 50 Prozent erwies sich der alte Traktor dem neuen als eindeutig überlegen. Der Schwager schaute sich daraufhin interessiert die beiden randomisierten Studien an und begann zu schmunzeln. Verunsichert bat der Landwirt um eine Erklärung. Der Schwager erklärte ihm, dass er hier Opfer eines Phänomens geworden ist, dass jedem Wissenschaftler geläufig ist: Es handelt sich um die externe Validität oder Übertragbarkeit von Schlussfolgerungen aus wissenschaftlichen Studien. In allen wissenschaftlichen vergleichenden Studien werden durch sorgfältig ausgewählte Ein- und Ausschlusskriterien diejenigen Patienten charakterisiert, die in die Studie aufgenommen werden sollen. Die Ergebnisse der Studie beziehen sich natürlich nur auf die untersuchte Studiengruppe. Wenn die Studie ordentlich durchgeführt wurde, dann sind die Schlussfolgerungen für die Studiengruppe gültig. Das nennt man interne Validität. Es bleibt allerdings fraglich, ob die Schlussfolgerungen auch auf eine ähnliche Situation übertragbar sind. So sind zum Beispiel die Daten von „fast gesunden“ Studienpatienten aus pharmakologischen Studien auf die häufig sehr kranken Patienten im klinischen Alltag nicht übertragbar und damit die sogenannte externe Validität nicht gegeben.
Als der Landwirt den Schwager bei seinen Ausführungen mit den großen Augen des totalen Unverständnisses anschaute, erläuterte er die Zusammenhänge erneut. Die beiden vergleichenden randomisierten Studien über den Erfolg des neuen Traktor-Pflug-Systems waren nämlich in Oldenburg und Geesthacht durchgeführt worden, auf einem ebenen Ackerland mit völlig anderen Bodenverhältnissen. Die dort nachgewiesenen Vorteile sind natürlich auf ein hügeliges Ackerland in Thüringen nicht ohne weiteres übertragbar. Deshalb wundert auch nicht, dass die Vorteile bei dem Landwirt nur in einem Bereich seiner Ackerfläche nachweisbar ist, der weitgehend der norddeutschen Landschaft entspricht. Die Studien waren einwandfrei durchgeführt worden und entsprachen einem hohen wissenschaftlichen Niveau. Die interne Validität der gezogenen Schlussfolgerungen war sicher gegeben. Aber die externe Validität, d.h. die Übertragbarkeit auf eine andere Landschaft oder Bodenbeschaffenheit war nicht gegeben. Ohne Zweifel kann ein Landwirt in Emden oder Niebüll erwarten, dass in diesen Regionen die Schlussfolgerungen aus der Studie auch valide und übertragbar sind, aber eben nicht in anderen Landesteilen. Dazu wären weitere Studien erforderlich gewesen, die wahrscheinlich zu anderen Schlussfolgerungen geführt hätten. Eine Probestellung des Traktors statt eines Kaufes hätte hier schnell die Grenzen aufgezeigt und den Landwirt vor hohen Investitionskosten bewahrt.
Ein Jahr später hatte sich der Landwirt mittlerweile damit angefreundet, dass er nun zwei Traktoren warten und pflegen muss. Er hatte seine Scheune erweitert, um auch den zweiten Traktor einschließlich Pflug und Ausrüstung dort unterzubringen. Der alte Traktor musste zwischenzeitlich repariert werden. Der Nutzen durch die Vorteile des neuen Traktors haben die zusätzlichen Anschaffungs- und Unterhaltskosten bisher nicht gerechtfertigt, aber der Landwirt hofft, dass sich die Kosten in zehn Jahren amortisieren – vorausgesetzt der neue Traktor muss nicht repariert werden.
13.3 Schätzungen und Konfidenzintervalle
Indem wir von den Studienergebnissen auf die Grundgesamtheit schließen, schätzen wir zugleich auf zukünftige Ergebnisse. Wenn wir zum Beispiel den durchschnittlichen systolischen Blutdruck mit einem neuen Medikament um 35±12 mmHg in einer Studie gesenkt haben, dann schätzen wir ab, welche Ergebnisse wir bei unseren Patienten erwarten können. Aus Vergangenem schließen wir auf Zukünftiges. Wir schätzen oder wetten auf die Zukunft. Um aber gut abschätzen zu können, um die Zukunft verlässlich vorhersagen zu können, benötigen wir sichere Grundlagen. Wir benötigen verlässliche „Schlussregeln“. Diese sind leider mathematisch sehr komplex und basieren auf vielen Bedingungen, die für den Laien nicht offensichtlich sind. Aber der Statistiker weiß, dass jede verlässliche Schätzung auf Annahmen wie Erwartungstreue und Konsistenz beruht sowie der effizienten und erschöpfenden Aufbereitung der Informationen. Da diese Annahmen immer nur unvollständig erfüllt sein werden, sind unsere Schätzungen ungenau und fehleranfällig.
Mit der externen Validität einer Studie haben wir nun eine sehr wichtige Komponente einer Studie kennengelernt. Mit ihr können wir die Ergebnisse der Studie jetzt auch auf andere Situationen übertragen. Wenn die Studie extern valide ist, dann können wir erwarten, dass wir in einer vergleichbaren Situation zu ähnlichen Ergebnissen gelangen. Aber zu welchen genau? Wenn die Studie extern valide ist, bleibt es nicht allein bei der Aussage: die Ergebnisse sind übertragbar. Wir wollen auch wissen, in welchem Maße die Ergebnisse übertragbar sind. Welche genauen Ergebnisse könnten wir erwarten, wenn wir die Studie mit einer anderen Stichprobe unserer Population wiederholen? Würden exakt dieselben Ergebnisse eintreten? Wohl kaum. Wir würden immer eine Variabilität der Ergebnisse erwarten. Mit der Übertragbarkeit meinen wir also nicht, dass wir durch eine erneute Studie einen präzisen Wert reproduzieren, sondern dass der Wert sehr wahrscheinlich in einem bestimmten Intervall liegt.
Aufgrund der relativen Unsicherheit leiten wir aus den Daten einen 95%igen Vertrauensbereich ab. Was ist mit diesem 95%igen Konfidenzintervall gemeint? Es ist das Ergebnis einer Schätzung. Wir schätzen ein Intervall. Wir glauben, dass sich die Blutdruckverminderung bei wiederholten Versuchen innerhalb dieses Intervalls befindet. Wir unterstellen dabei wiederum eine Irrtumswahrscheinlichkeit von fünf Prozent – deshalb auch 95%ig. Es ist quasi ein Prognoseinstrument.
Das 95%-Konfidenzintervall sollte immer angegeben werden, wenn wir einen Effekt „übertragen“ wollen. Indem wir das Konfidenzintervall berechnen, was wir getrost Computerprogrammen überlassen können, überblicken wir den Therapieeffekt, den wir erwarten können. Wenn wir ein neues Operationsverfahren einführen, das die Operationszeit im Durchschnitt um 20 Minuten verkürzt, dann ist diese Information unvollständig. Wir würden jetzt erwarten, dass der Untersucher uns mit dem Konfidenzintervall mitteilt, in welchem Bereich wir mit 95%iger Wahrscheinlichkeit einen Effekt erwarten können.
Die Breite des Vertrauensbereiches ist entscheidend. Wenn das Konfidenzintervall nur 15-25 Minuten beträgt oder sich immer weiter verbreitert zu 2-35 Minuten oder gar zu (-5)-45 Minuten, dann hegen wir eine unterschiedliche Erwartungshaltung. Je weiter das Konfidenzintervall ist, umso unsicherer ist der Therapieeffekt, den wir erwarten können. Je enger das Konfidenzintervall ist, umso sicherer sind wir, dass wir auch in den Genuss des Vorteils gelangen.
Wovon hängt die Weite des Konfidenzintervalls ab? Was können wir tun, um ein enges Konfidenzintervall zu erhalten? Das Intervall hängt sowohl von der Streuung der Daten als auch von der Anzahl der untersuchten Studienteilnehmer ab. Blicken wir auf das Kapitel 17 zurück. Hier hatten wir in den Abbildungen Dreiecke dargestellt. Die Breite der Dreiecke entsprach dem Ausmaß der Streuung. Je breiter die Basis, umso weiter streuten die Daten. Die Breite des Dreiecks verschmälerte sich nach oben mit der Zunahme der Studienpopulation, die wir als „Schlankmacher“ für unseren Signifikanztest bezeichneten. Je mehr Patienten, Tiere oder Ereignisse wir untersuchen, umso schmaler wir das Konfidenzintervall. Je mehr Ereignisse wir untersuchen, umso sicherer sind wir mit unserer Schätzung. Eine Studie mit 1000 Ereignissen lässt uns sicherer sein, als wenn wir nur 100 Patienten eingeschlossen haben.
Wir müssen das 95%-Konfidenzintervall unbedingt von den 5%-95%-Box-Plots unterscheiden. Wenn wir eine Studie durchführen, dann präsentieren wir unsere Daten, indem wir Mittelwerte, Standardabweichungen, relative und absolute Häufigkeiten angeben oder die Ergebnisse durch Box-Plots oder Balkendiagramme abbilden. In den Box-Plots stellen wir üblicherweise die 5%-95%-Perzentilen dar. Diese haben aber nichts mit dem 95%-Konfidenzintervall zu tun, wenn wir von „95%“ einmal absehen. Bei den Box-Plots handelt es sich um die Beschreibung unserer tatsächlichen Daten (deskriptive Statistik).
Mit dem Konfidenzintervall drücken wir dagegen eine Schätzung aus (induktive Statistik), welchen Effekt wir zwischen den Gruppen erwarten können, wenn wir die Studie wiederholen würden. Sie gibt uns ein Maß für einen Erwartungswert, den wir an die Therapien stellen können.
13.4 p-Wert und Konfidenzintervall
In heutigen wissenschaftlichen Publikationen wird immer gefordert, die 95%-Konfidenzintervalle anzugeben. Sie sind wichtiger als die p-Werte. Warum werden die Konfidenzintervall gefordert? Was können wir aus ihnen ablesen?
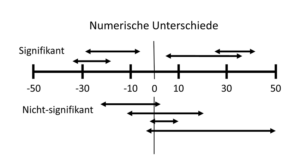
Abb. 13-2 Konfidenzintervalle bei numerischen Unterschieden
Die Konfidenzintervall vermitteln uns eigentlich alle Auskünfte, die wir uns wünschen. Ersten teilen sie uns mit, welchen Therapieeffekt wir zu erwarten haben, und zweitens weisen sie auch daraufhin, ob der Unterschied zwischen den Gruppen signifikant ist. Wenn wir nämlich einen numerischen Unterschied von 30 Einheiten zwischen zwei Gruppen finden, dann können wir aus dem Konfidenzintervall leicht ablesen, ob der Unterschied auch signifikant war. Beträgt das Konfidenzintervall 10-50 Einheiten und liegt damit nicht jenseits der Null, dann ist der Unterschied signifikant. Beträgt das Konfidenzintervall dagegen (-5)-65, dann erkennen wir auf einen Blick, dass der Unterschied nicht-signifikant ist (Abb. 13-2).

Abb. 13-3 Konfidenzintervalle bei relativem Risiko
Ähnlich verhält es sich auch, wenn wir das relative Risiko (RR) berechnen. Unterscheiden sich zwei Gruppen nicht, dann beträgt RR exakt 1. Ist das Risiko doppelt so hoch, dann ist RR gleich 2 und wenn es fünf Mal so hoch ist, dann ist RR gleich 5. Würde sich das Risiko halbieren, dann wäre RR gleich 0,5 und bei einer Abnahme um 25% wäre RR gleich 0, 75. Beim Relativen Risiko liegt die Scheidegrenze zwischen einem signifikanten und nicht-signifikanten Unterschied bei 1. Wenn vom Konfidenzintervall die 1 überschritten wird, dann ist der Unterschied nicht-signifikant (Abb. 13-3). Egal, wie groß das Intervall ist.